Web开发技术—实验1 实验1:Web服务器 搭建Web服务器,正确部署任意网站,并利用浏览器访问(可以尝试如何支持不同版本的HTTP协议)
目前市场上有很多的Web服务器,如Apache,IIS,Nginx,Tomcat,Lighttpd,Zeus等等。截止2020年8月,Nginx市场份额达到了36%,成为排名第一的Web服务器。因此本次实验通过Nginx搭建Web服务器。以Linux Debian为系统,进行nginx安装。安装过程中报错,一般是缺少依赖库,搜索报错即可解决。
1 sudo apt-get install nginx
安装后查看nginx安装位置:
进入/etc/nginx,目录下nginx.conf为Nginx的配置文件,打开添加server配置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 user www-data; #配置用户或者组,默认为nobody nobody worker_processes auto; #允许生成的进程数,默认为1 pid /run/nginx.pid; #指定nginx进程运行文件存放地址 include /etc/nginx/modules-enabled/*.conf; events { worker_connections 768; #最大连接数,默认为512 # multi_accept on; #设置一个进程是否同时接受多个网络连接,默认为off } http { ## # Basic Settings ## sendfile on; #允许sendfile方式传输文件,默认为off,可以在http块,server块,location块 tcp_nopush on; #必须在sendfile开启模式才有效,告诉nginx在一个数据包里发送所有头文件,而不一个接一个的发送。 types_hash_max_size 2048; # server_tokens off; # server_names_hash_bucket_size 64; # server_name_in_redirect off; include /etc/nginx/mime.types; default_type application/octet-stream; ## # SSL Settings ## ssl_protocols TLSv1 TLSv1.1 TLSv1.2 TLSv1.3; # Dropping SSLv3, ref: POODLE ssl_prefer_server_ciphers on; ## # Logging Settings ## access_log /var/log/nginx/access.log; #combined为日志格式的默认值 error_log /var/log/nginx/error.log; ## # Gzip Settings ## gzip on; #开启页面压缩 # gzip_vary on; # gzip_proxied any; # gzip_comp_level 6; # gzip_buffers 16 8k; # gzip_http_version 1.1; # gzip_types text/plain text/css application/json application/javascript text/xml application/xml application/xml+rss text/javascript; ## # Virtual Host Configs ## include /etc/nginx/conf.d/*.conf; include /etc/nginx/sites-enabled/*; server { listen 10.122.200.178:80; #监听端口 server_name localhost; #监听地址 location / { #请求的url过滤,可为正则匹配,~为区分大小写,~*为不区分大小写。 root /home/llrber/桌面; #根目录 index index.html; #设置默认页 } } }
主要是加server内的内容,其中监听端口80(因为我虚拟机同时配置了apache,所以为了避免端口冲突才在前面加入了本机IP)。root为浏览器访问的根目录,这里选用的为桌面,其中放入html相关的代码文件,index为打开的默认页。
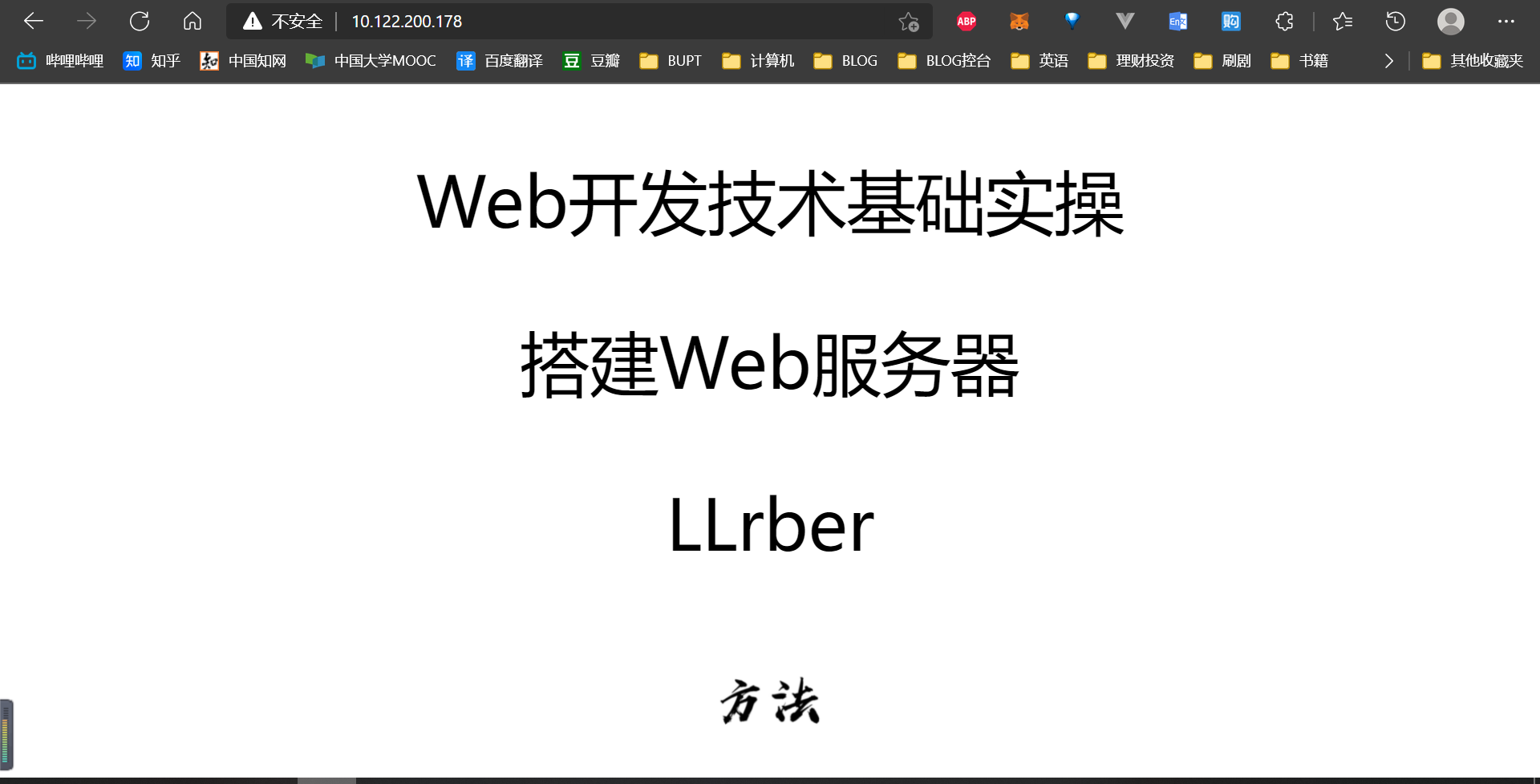
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 <!doctype html > <html lang ="en" > <head > <meta charset ="UTF-8" > <meta name ="viewport" content ="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0" > <meta http-equiv ="X-UA-Compatible" content ="ie=edge" > <title > Web开发技术基础实操</title > <style > p { font-size : 10vh ; text-align : center; } img { margin-left : 46% ; height : 100px ; width : 100px ; } </style > </head > <body > <div > <p > Web开发技术基础实操</p > <p > 搭建Web服务器</p > <p > LLrber</p > <img src ="https://lrblog-img-1304667442.file.myqcloud.com/method.jpg" > </div > </body > </html >
配置好后重启nginx服务。
1 /etc/init.d/nginx restart
成功后可以通过本机的IP地址访问搭建的网站了。可以ifconfig查询本机IP。
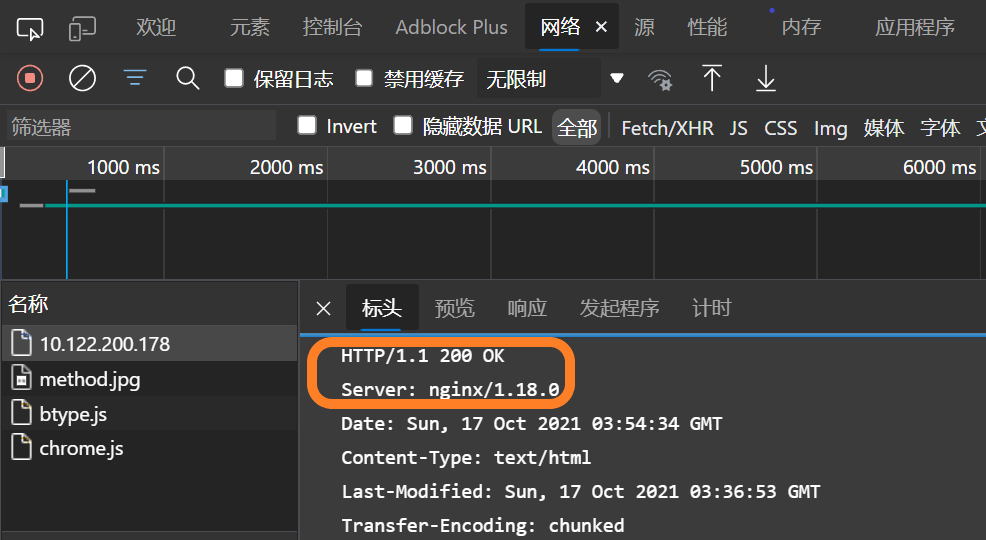
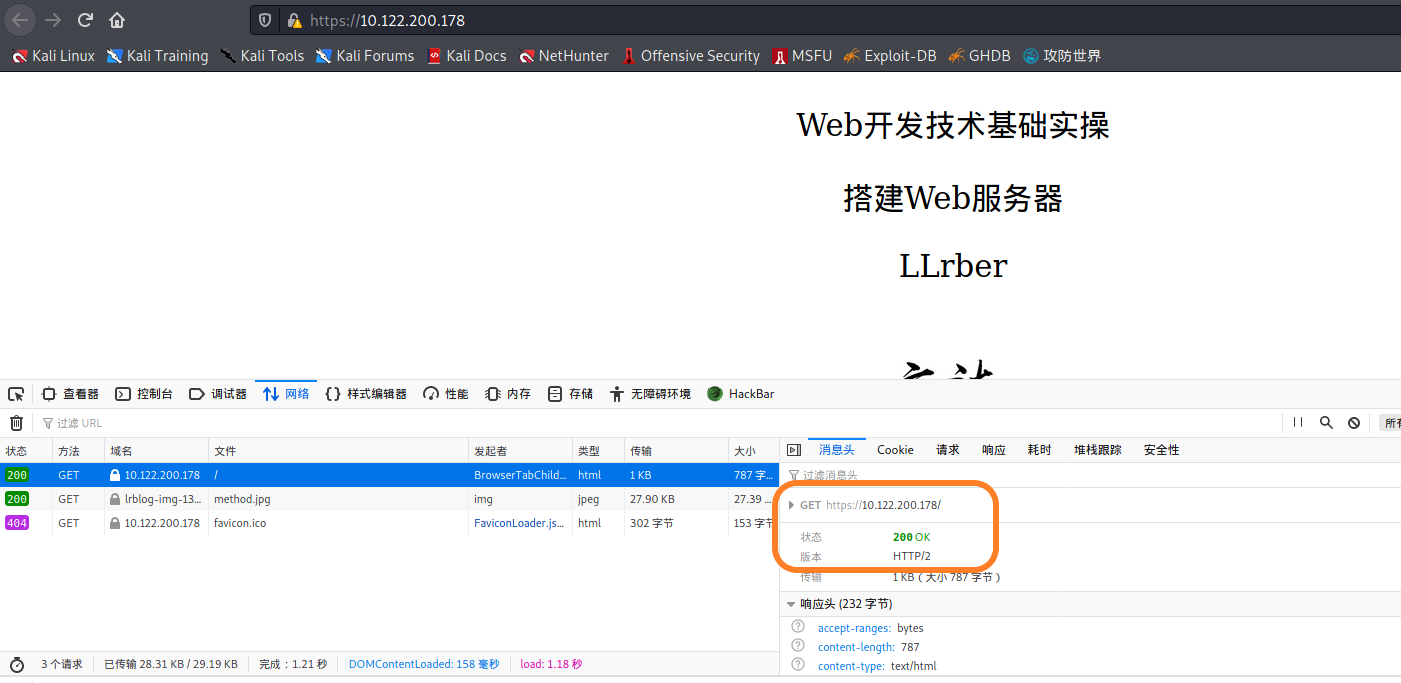
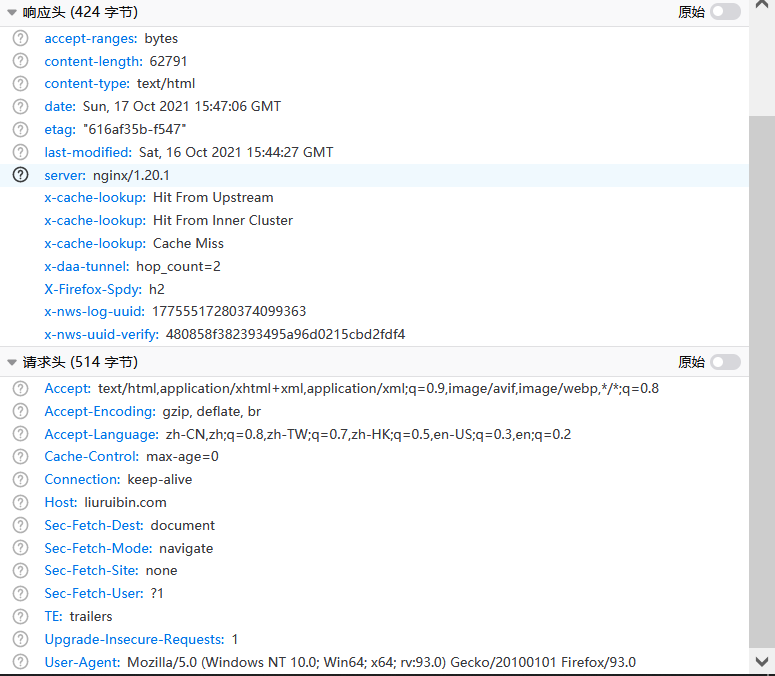
利用浏览器的检查的network,可以查看到http当前的版本和Web服务器信息。
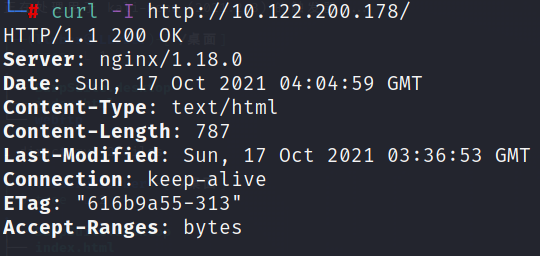
或者,通过curl指令请求Web服务器,也可查看。
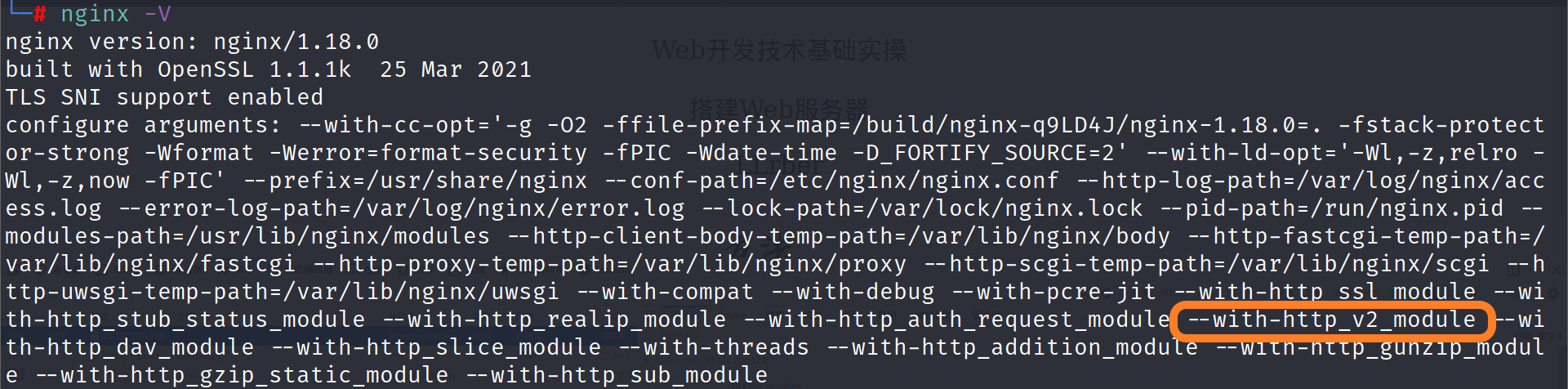
nginx在最新版本中已经支持HTTP/2的协议,可以通过nginx -V来查验。
因为HTTP/2需要开启SSL支持,所以需配置SSL和更改nginx的配置。添加SSL支持需要添加证书,一种方式是购买或者在网上有一些免费的SSL证书可用,如果只是在测试环境中的话,还可以生成自签名证书。这里使用openssl命令来完成生成自签名证书这个工作。
openssl详情
openssl是一个非常强大的密钥生成工具,可以完成绝大多数的密钥生成工作。
req表示的是这是一个X.509 certificate signing request (CSR)。
-x509表示我们希望生成的是一个自签名的证书。
-nodes表示我们不需要对生成的密钥进行密码加密。
-days 365表示证书的有效期。
-newkey rsa:2048表示使用RSA算法同时生成证书和key,key的长度是2048。
-keyout:指定key的生成路径。
-out:指定证书的生成路径。
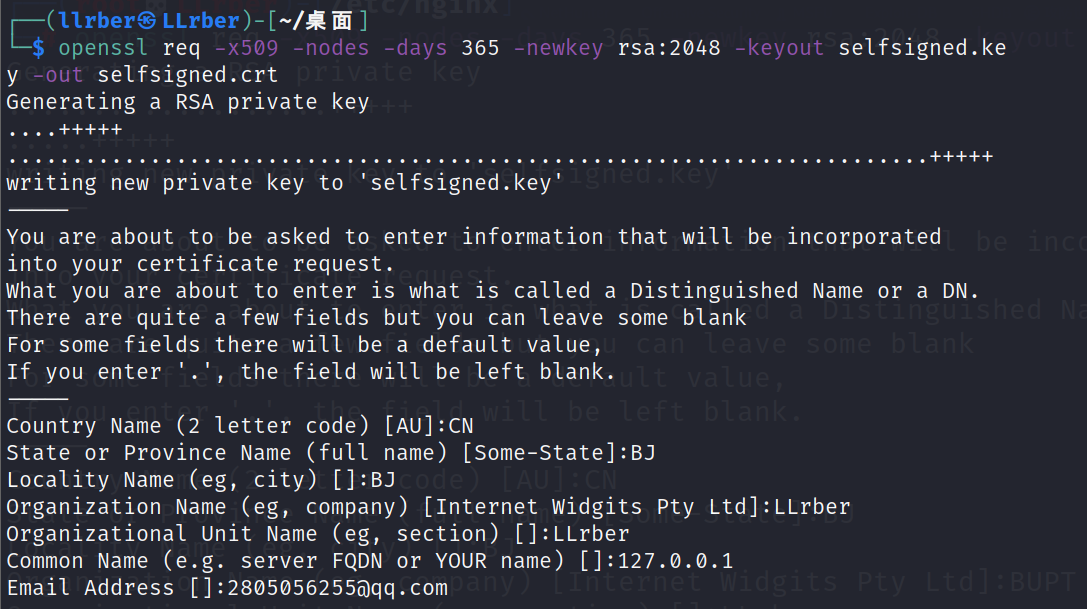
1 openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout selfsigned.key -out selfsigned.crt
我是在桌面运行的,为了好找到生成的文件。输入后会要求填写一些证书的相关信息,完成后就会在当前目录下生成了两个文件:selfsigned.crt和selfsigned.key。
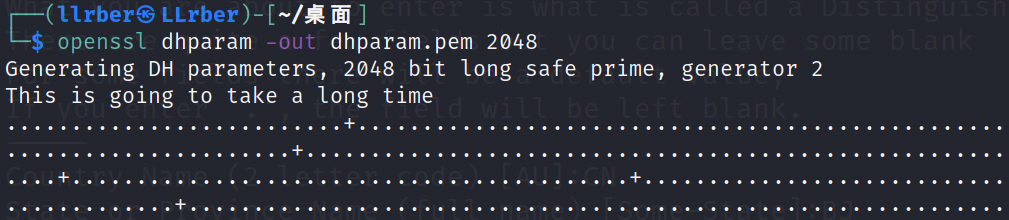
这里即使是使用了SSL,为了保证安全,我们还可以使用一项叫做完美的向前保密的技术,这里需要生成Diffie-Hellman group:
1 openssl dhparam -out dhparam.pem 2048
运行完成即可。再配置nginx.conf,主要就是修改了server部分。
1 2 3 4 5 6 7 8 9 10 11 server { listen 443 ssl http2; server_name 10.122.200.178; ssl_certificate /home/llrber/桌面/selfsigned.crt; ssl_certificate_key /home/llrber/桌面/selfsigned.key; location / { root /home/llrber/桌面; index index.html; } }
之后重启nginx服务/etc/init.d/nginx restart。打开浏览器验证HTTP协议版本号。用https进入时会提醒网站不安全,只要选择高级-继续访问即可。
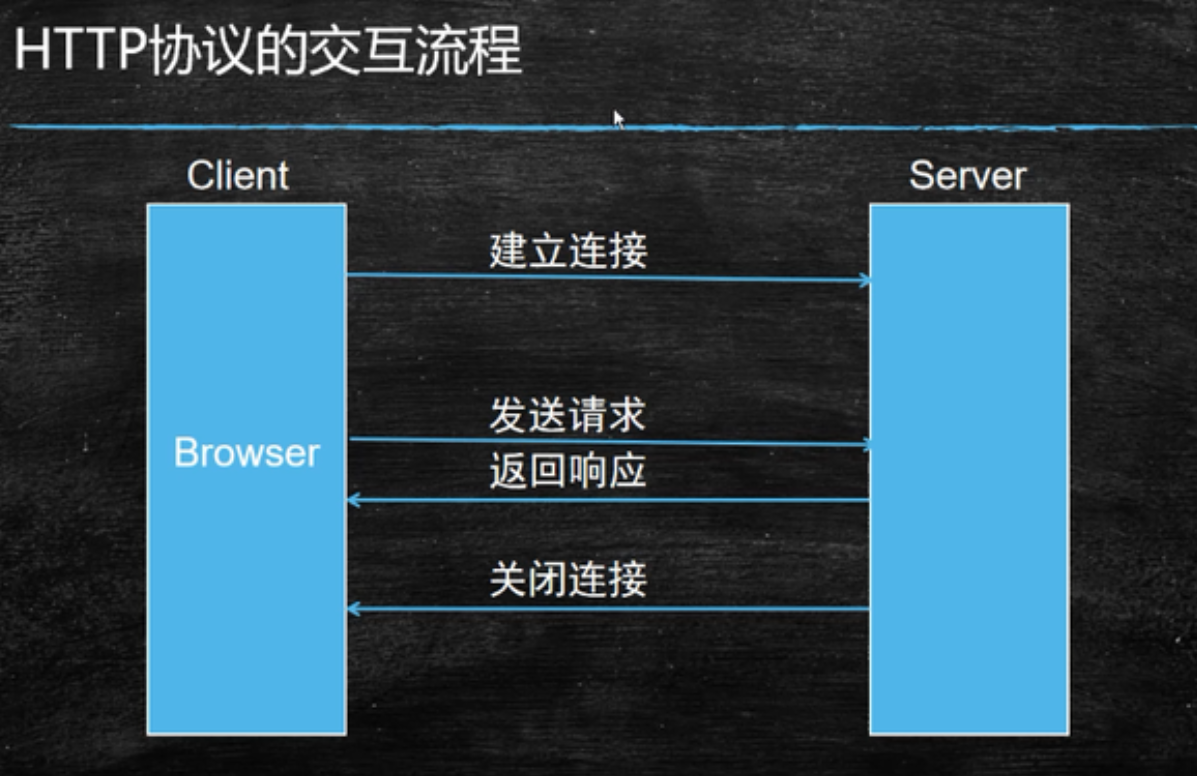
实验2:HTTP协议 访问任意Web网站首页,利用浏览器的Web开发工具观察HTTP交互过程和涉及到的HTTP头部字段。
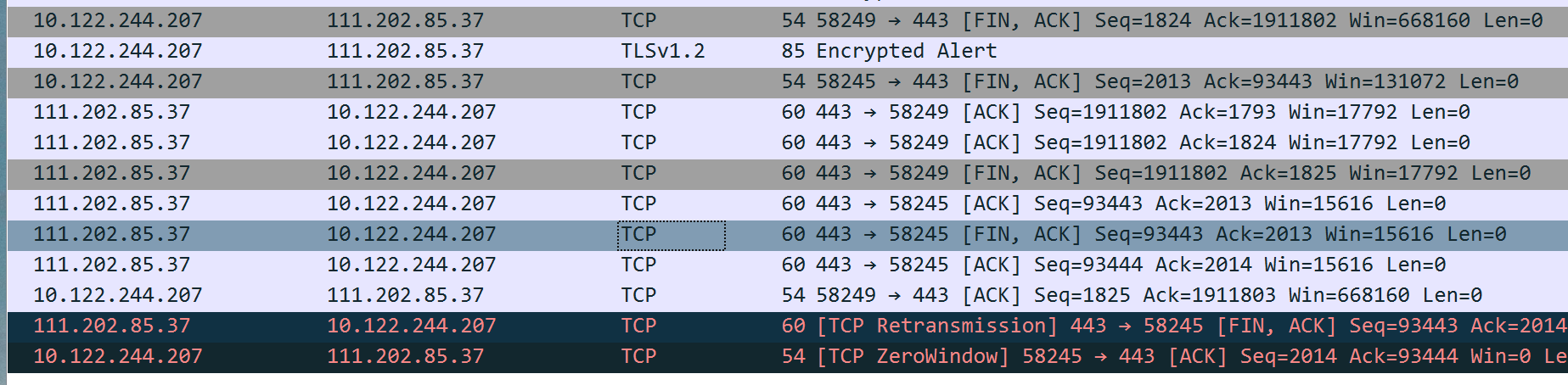
HTTP协议为应用侧协议,其通过TCP,或者TLS(加密的TCP连接来发送)。TCP三次握手创立连接。
请求与响应头
四次挥手断开连接。
实验3:自动化无头浏览器 利用自动化测试工具操纵无头浏览器,进行网页爬虫、截图等实验。
首先,解释下无头浏览器,其指可以在没有图形界面情况下运行的浏览器。可以通过编程来控制无头浏览器自动执行各种任务,比如爬虫,网页截屏,DDoS等。
在之前学习网络爬虫时,就接触到过selenium模块,其为一个Web自动化测试工具,既可以自动化操作有图形界面的浏览器,也可以操作无头浏览器在后台操作,其中的原理是相近的,因此需要同第三方浏览器结合使用。
安装selenium。
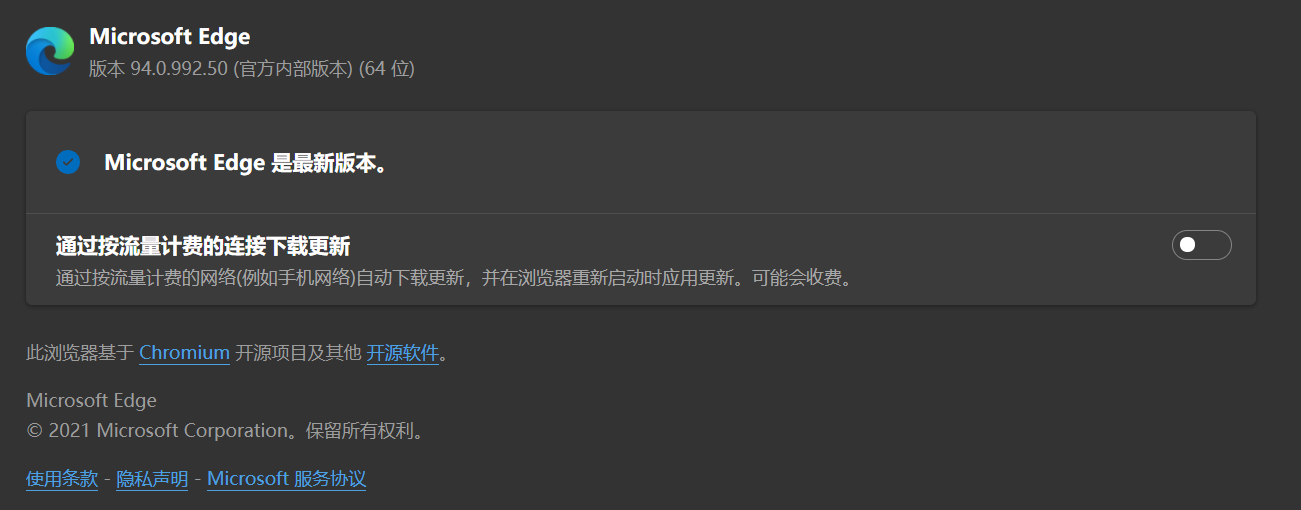
配置webdriver, 查看自己电脑Microsoft Edge的版本,设置-关于Microsoft Edge。
前往微软官方网站下载Microsoft Edge的webdriver ,找到与自己浏览器对应的版本下载,解压后得到一个msedgedriver.exe。
然后,可以将msedgedriver.exe放在python的安装目录下。
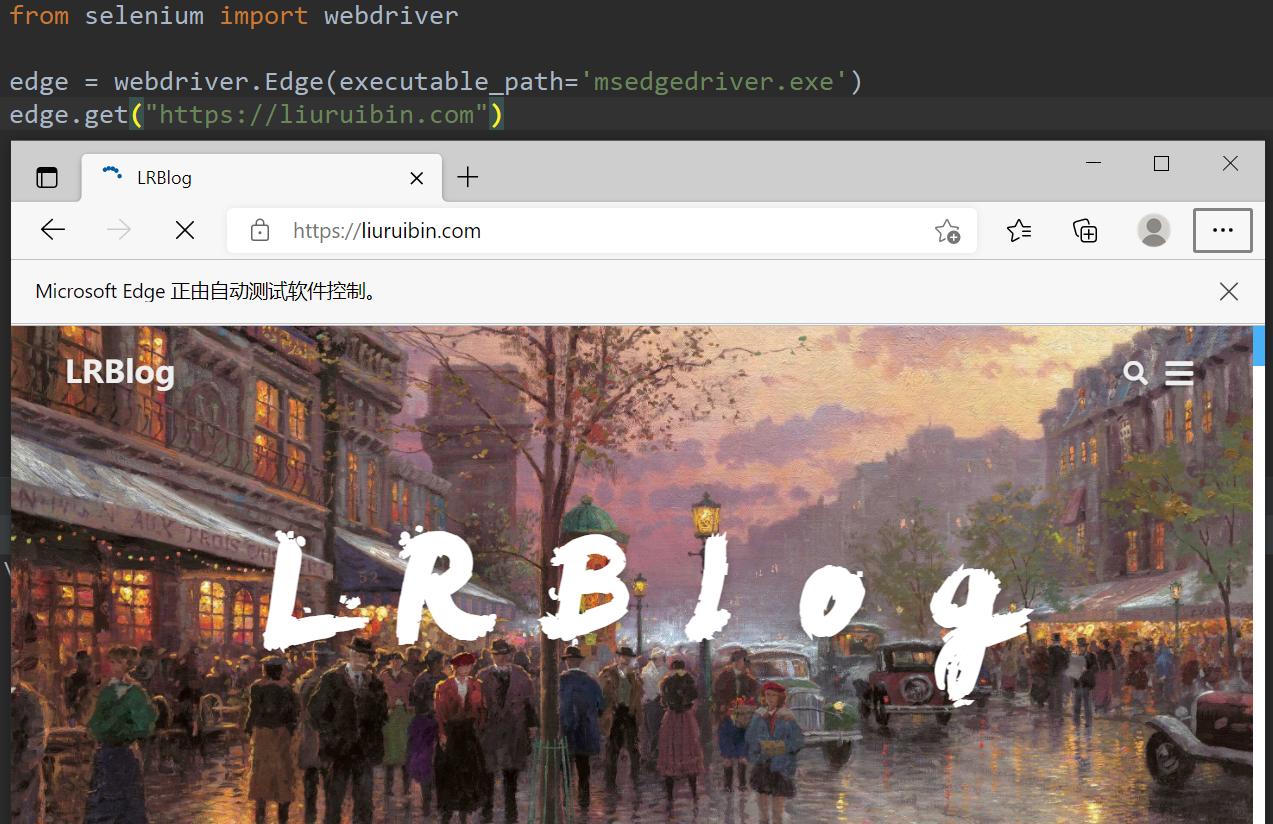
简单的编写下程序,验证是否能够自动启动浏览器。需要注意的是填写executable_path是因为源文件中默认的驱动名称与实际名称不一致,所以要添加这个参数更改。
目前为止,只是初步的自动化启动浏览器,并没有做到爬虫等功能,并且也并不是无头浏览器的状态,需要更进代码完成。
之前使用过chrome的无头浏览器自动化,因为selenium封装了chrome和firefox的配置函数,但是Edge需要安装与selenium的链接库才可以进行配置。
1 pip install msedge-selenium-tools
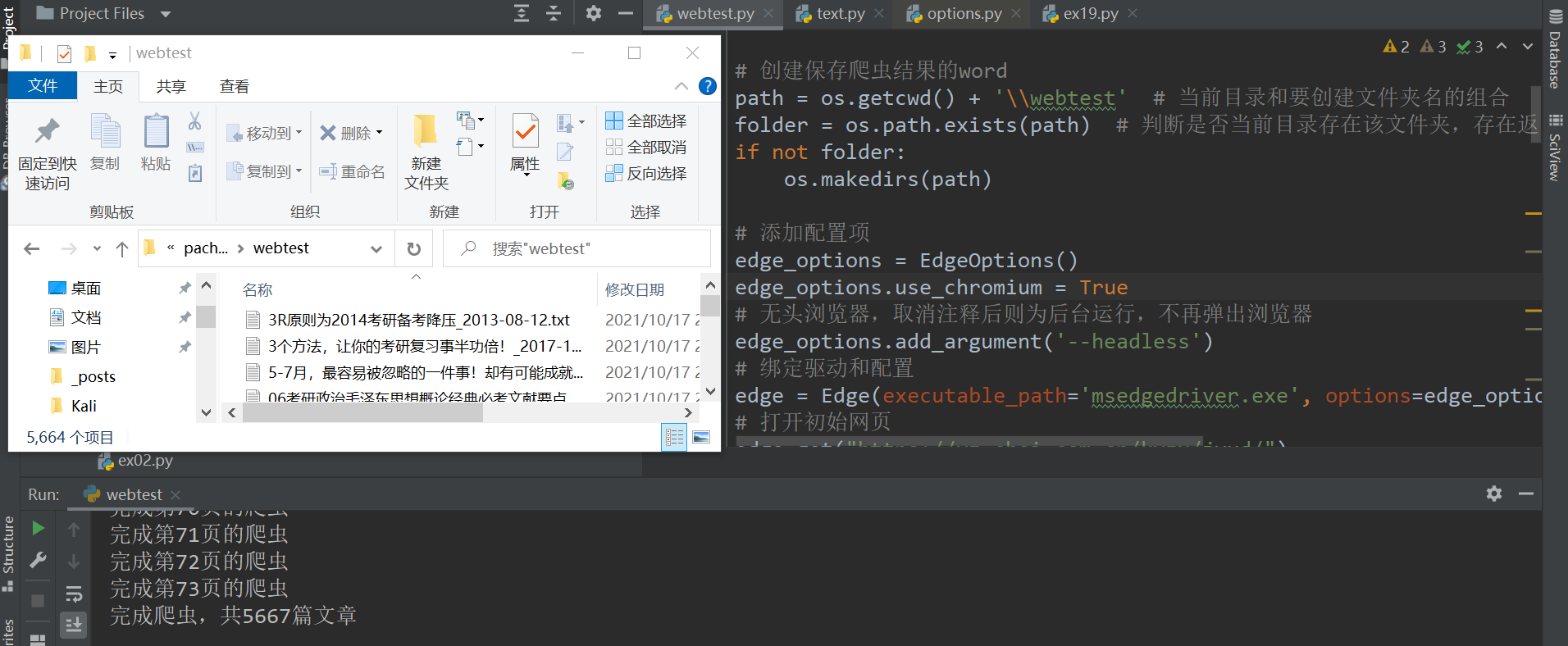
以研招网的经验心得为例,将其文章爬取下来。根据开发者工具定位模拟人的操作进行文章内容的爬取。edge_options.add_argument('--headless')将其取消注释即可为后台运行,代码如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 import osimport refrom msedge.selenium_tools import EdgeOptionsfrom msedge.selenium_tools import Edgefrom selenium.common.exceptions import NoSuchElementExceptionfrom selenium.webdriver.support.wait import WebDriverWaitpath = os.getcwd() + '\\webtest' folder = os.path.exists(path) if not folder: os.makedirs(path) edge_options = EdgeOptions() edge_options.use_chromium = True edge = Edge(executable_path='msedgedriver.exe' , options=edge_options) edge.get("https://yz.chsi.com.cn/kyzx/jyxd/" ) end_state = 0 page_count = 0 passage_count = 0 while True : ul = edge.find_element_by_class_name("news-list" ) li_list = ul.find_elements_by_xpath("li" ) for i in li_list: a = i.find_element_by_xpath("a" ) title = a.text title = re.findall(r'[^\*"/:?\\|<>]' , title, re.S) title = "" .join(title) time = i.find_element_by_class_name("span-time" ).text try : a.click() WebDriverWait(edge, 60 , 1 , NoSuchElementException).until( lambda edge: edge.find_element_by_class_name("ch-sticky" )) except NoSuchElementException as e: edge.refresh() print ("页面没刷新出来,又刷新了一次" ) edge.switch_to.window(edge.window_handles[-1 ]) new_window = edge.current_window_handle content = edge.find_element_by_class_name("content-l" ) with open (os.getcwd() + '\\webtest\\' + title + "_" + time + ".txt" , "w" , encoding='utf-8' ) as f: f.write(content.text) edge.close() edge.switch_to.window(edge.window_handles[-1 ]) new_window = edge.current_window_handle passage_count += 1 page_count += 1 next = edge.find_element_by_link_text("下一页" ).get_attribute("href" ) end = edge.find_element_by_link_text("末页" ).get_attribute("href" ) print ("完成第" + str (page_count) + "页的爬虫" ) if end_state == 1 : break page = edge.find_element_by_link_text("下一页" ) try : page.click() WebDriverWait(edge, 60 , 1 , NoSuchElementException).until( lambda edge: edge.find_element_by_class_name("ch-sticky" )) except NoSuchElementException as e: edge.refresh() print ("页面没刷新出来,又刷新了一次" ) if next == end: end_state = 1 edge.quit() print ("完成爬虫,共" + str (passage_count) + "篇文章" )
这次实操中仅仅是利用了selenium的元素定位和内容的获取,其最魅力的地方还是自动化。关于截图也有很多有意思的地方,比如可以多张截图拼接成整个网页的样子。当然,也结合更多的配置和微信小程序。
个人观点,selenium自动化比较细节化,因此代码专项性很强,但需要面对不同需求而特定编写。
鸣谢❀参考大佬文章